Notre site dispose désormais d'un mode éco. N'hésitez pas à l'essayer !
Notre site dispose désormais d'un mode éco. N'hésitez pas à l'essayer !
Elle n'aura pas duré longtemps, mais l'époque où le server side tagging semblait inaccessible est déjà révolue.
Le server side tagging est une nouvelle approche révolutionnaire de la gestion des données analytiques et marketing sur les sites web et les applications mobiles. Contrairement au client side tagging traditionnel, qui s'exécute sur le navigateur de l'utilisateur, le server side tagging traite les données sur le serveur, offrant ainsi de nombreux avantages en termes de performance, de sécurité et de respect de la vie privée.
Cependant, malgré toutes ces promesses, nombreux sont les sites à ne pas encore avoir sauté le pas, principalement pour des raisons de coût, le server-side tagging nécessitant une infrastructure dédiée et une capacité de traitement relativement élevée, mais aussi pour des raisons de complexité et d’accessibilité, dans la mesure où il s’agit d’une toute autre manière de collecter et de traiter de la donnée.
N’ayant nous-mêmes pas franchi le pas, nous nous sommes prêtés à l’exercice en utilisant RudderStack, une plateforme de server-side tagging offrant une grande flexibilité et une simplicité de prise en main remarquable.
Je vais donc vous présenter dans cet article la manière dont j’ai pu mettre en place un système de server-side tagging sur un site e-commerce en m’affranchissant des contraintes sus-mentionnées : mon server-side tagging ne m’a rien coûté et a pu être mis en place en moins d’une heure.
RudderStack est une plateforme de Customer Data Platform (CDP) open-source qui offre une solution complète de server side tagging. Présente sur le marché depuis plusieurs années, la plateforme propose différentes solutions clés en main pour passer au server-side tagging :
Ce qui a attiré mon attention sur Rudderstack, c’est un article diffusé sur le blog de la plateforme présentant une arme redoutable pour le server side tagging, avec la promesse d’une transition facile et d’une maitrise des coûts : le mode hybride.
Le mode Hybride de RudderStack est une innovation majeure qui permet de combiner le server side et le client side tagging. Cette flexibilité est particulièrement utile pour s'adapter aux différents contextes et maximiser la couverture des données, tout en respectant le consentement des utilisateurs.
Concrètement, RudderStack peut fonctionner en mode server ou client selon le contexte, et les données collectées sont ensuite routées vers les destinations sélectionnées en utilisant le mode le plus approprié. Cette approche offre de nombreux avantages, tels que la performance, la couverture des données et le respect du consentement.
Cette fonctionnalité m’a semblé être un bon moyen de transposer mon client-side tagging en server-side, sans risquer d’exploser les coûts. En effet, les données transitent via le front-end lorsque c’est possible, limitant ainsi les frais de cloud nécessaires en server-side tagging.

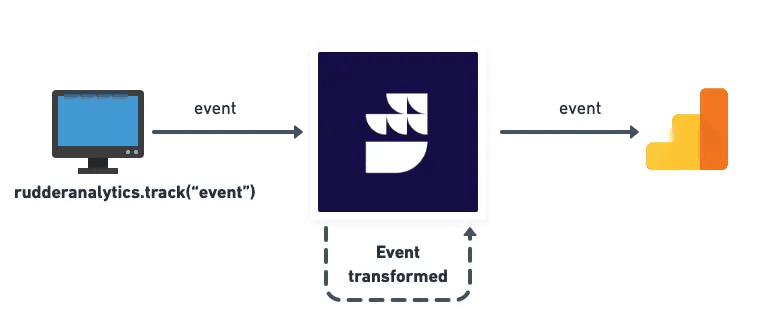
Pour le tagging de notre site, nous utilisons la méthode du Datalayer. L’idée est donc qu’à chaque événement, une fonction Javascript envoie un push et remplisse le Datalayer. Ce dernier est ensuite récupéré par Google Tag Manager qui renvoie ces événements vers GA4, Meta, ou toute autre plateforme.
Cette méthode présente plusieurs avantages :
Voici un exemple concret :
Lorsqu’un utilisateur clique sur une question de la FAQ, cette fonction se déclenche :
var question = $(this).text().trim();
datalayerpush({
"event": "gtmdlv",
"event_name": "faq",
"element": question,
});Nous récupérons l’intitulé de la question, et envoyons un événement générique “gtmdlv” qui comporte le nom réel de l’événement en paramètre, ainsi que d’autres paramètres, dont la question qui a été cliquée. GTM reçoit ensuite l’événement “gtmdlv” et renvoie cet événement vers GA4, mais en prenant event_name comme le nom réel de l’événement.
Ensuite, tous les paramètres possibles sont ajoutés à l’événement.
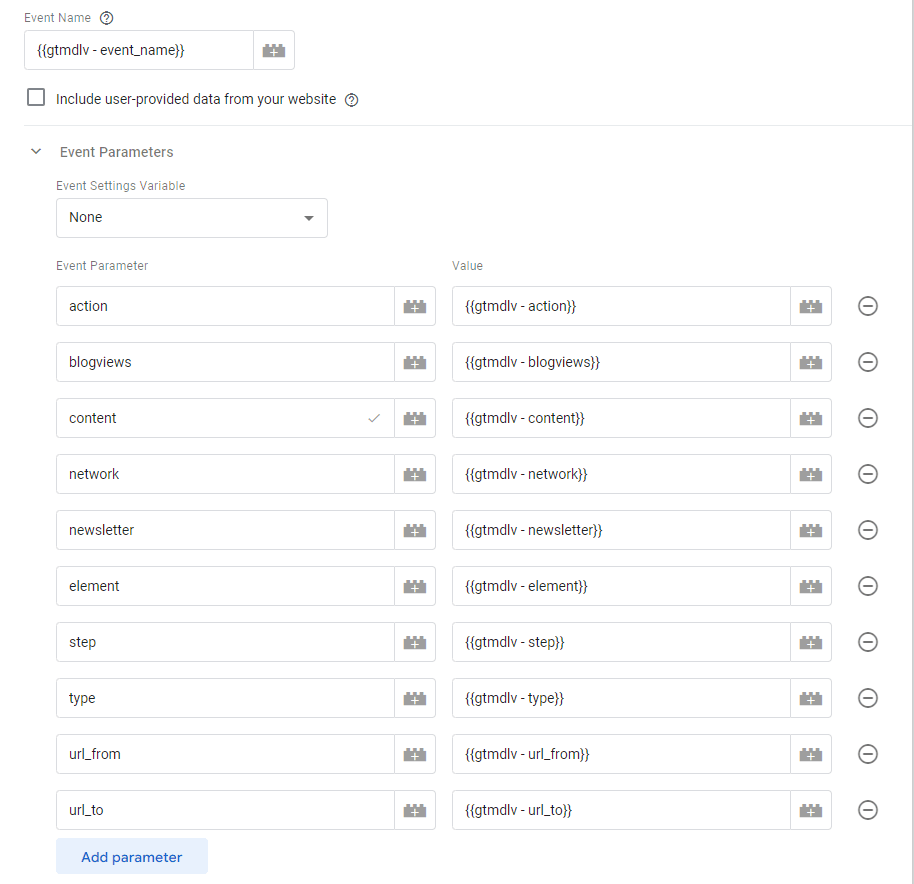
Plutôt que d’envoyer directement l’événement via un datalayer.push(), nous avons réécrit une fonction datalayerpush() qui fera elle-même l’envoi dans le datalayer. Cela nous permet passer sur tous les paramètres d'événement et de régler sur “undefined” tous ceux qui ne sont pas utilisés dans l’événement et donc d’éviter d’hériter d’une ancienne valeur.
var event_keys = ["event_name", "action","blogviews","content", "network","newsletter","element","step","type","url_from","url_to"];
function datalayerpush(parameters) {
window.dataLayer = window.dataLayer || [];
event_keys.forEach(function(key) {
if(!parameters[key]) parameters[key] = undefined;
})
dataLayer.push(parameters);
}Mais c’est aussi cette fonction qui nous a permis de décliner notre tagging sur Piwik PRO, Matomo, et dans ce cas précis, sur RudderStack, comme nous le verrons ci-après.
Pour réaliser notre Server-Side Tagging avec RudderStack, nous avons créé un compte gratuit. Celui-ci nous limite à 1000 événements par minute, ce qui est largement suffisant dans notre cas.
Mise en place des connexions
Une fois le compte créé, nous sommes invités à créer des connexions. Les connexions sont simplement un assemblage de deux composants :
Pour conserver le principal de mon tagging actuel, je choisis Javascript comme source et GA4 comme destination.
Ma connexion est donc établie.

Mise en place des transformations
RudderStack permet de gérer des transformations sur vos données. Cela peut être très utile pour reformatter certaines informations (renommer une donnée, remplacer des “null” par des 0, etc.).
RudderStack a également inclus un certain nombre de transformations pré-établies comme par exemple l’anonymisation automatique de certaines données, le hasahage, le filtrage de trafic robot, etc.
Dans notre cas, nous n’avons pas ajouté de transformation car celles-ci sont effectuées à la source, en Javascript.
Envoi des événements vers Rudderstack
Notre connexion JS→GA4 étant établie, RudderStack nous donne une structure de code permettant d’effectuer des push. Concrètement, il s’agit de la même chose qu’un dataLayer.push(), sauf que dans ce cas précis la fonction s’intitule rudderanalytics.track().
Nous devons donc repasser sur l’intégralité de notre tagging pour qu’à chaque fois qu’un dataLayer.push a lieu, un rudderanalytics.track ait lieu avec les mêmes événements et paramètres.
rudderanalytics.track(
'event name', {
'parameter': 'value',
'parameter': 'value'
},
() => {
console.log("track call");
}
);Et c’est là que notre fonction réécrite prend tout son sens, car étant donné que tous les événements passent par cette fonction, il est très facile d’ajouter un envoi vers RudderStack simultanément à l’envoi vers le Datalayer.
var event_keys = ["event_name", "action","blogviews","content", "network","newsletter","element","step","type","url_from","url_to"];
function datalayerpush(parameters) {
window.dataLayer = window.dataLayer || [];
event_keys.forEach(function(key) {
if(!parameters[key]) parameters[key] = undefined;
})
dataLayer.push(parameters);
rudderanalytics.track(
parameters['event_name'], {
parameters
},
() => {
console.log("track call");
}
);
}Juste après la mise en place du tracking avec RudderStack, j’ai voulu m’assurer de plusieurs choses :
Donc à priori rien n’a changé entre le client-side et le server-side. J’ai donc décidé de mener quelques tests et de laisser les deux outils fonctionner pour apprécier l’intérêt de RudderStack et de son mode hybride. Et comme chacun le sait, la promesse du server-side tagging, c’est de perdre le moins de données possibles dans un contexte où l’utilisation des cookies est de plus en plus contrainte.
Lors de ce test, notre conteneur GTM était configuré avec le Consent Mode V2, respectant scrupuleusement le consentement des utilisateurs.
Une semaine après l’installation de RudderStack, les résultats sont déjà probants : RudderStack a monitoré environ deux à sept fois plus d’événements que GA4 :
| Event name | RudderStack Count | GA4 Count |
|---|---|---|
| blog | 328 | 141 |
| navigation | 86 | 18 |
| configurator_start | 37 | 15 |
| media | 27 | 4 |
| configurator_doorstep | 19 | 3 |
| popup | 8 | 0 |
| faq | 6 | 0 |
| configurator_calculate | 5 | 0 |
| configurator_load | 4 | 0 |
| page_views_popup | 4 | 0 |
| configurator_restart | 1 | 0 |
| share | 1 | 0 |
Nous savions que GA4 pouvait échantilloner les données présentées et que le client-side tracking ne couvrait pas 100% des données de visite, mais la différence que nous observons entre ces deux collectes de données est sans appel et confirme bien l’importance du server-side tracking : il permet d’obtenir des données exhaustives et donc de prendre les bonnes décisions stratégiques, en toute connaissance de cause.
RudderStack agit donc comme une bouée de secours pour mon tracking : lorsque le tracking classique en client-side ne fonctionne pas (bloqueur de publicité, problèmes techniques, etc.), RudderStack prend le relais et transmet les données qui n’auraient normalement pas été transmises.
Vous souhaitez effectuer un test du mode Hybride de RudderStack sur votre site web ? Vous souhaitez simplement plus de renseignements sur le server-side tagging ? N'hésitez pas à solliciter nos experts !